I. Lời mở đầu
Nhận dạng cấu trúc bảng là một vấn đề tương đối phức tạp trong bài toán xử lý và phân tích cấu trúc của một văn bản. Dữ liệu bảng được sử dụng rộng rãi trong các loại văn bản và chứa rất nhiều thông tin. Chúng ta có thể nhìn thấy dữ liệu dạng bảng trong nhiều lĩnh vực, trong nhiều cơ quan hành chính chính phủ hay các công ty như ngân hàng,... Họ đều phải xử lý hàng triệu dữ liệu bảng mỗi ngày.
Trong những năm gần đây, chúng ta đã nghe nhiều đến cụm từ "số hóa dữ liệu". Tuy nhiên quá trình số hóa dữ liệu này đang gặp nhiều khó khăn trong việc chuyển đổi những văn bản dạng scan đặc biệt đối với những văn bản có chứa bảng thành văn bản số có thể chỉnh sửa đang gặp rất nhiều thách thức. Con người chúng ta có thể dễ dàng tiếp thu và hiểu được thông tin dạng bảng nhưng ngược lại máy tính rất khó khăn để làm được điều đó.
Hôm nay chúng ta cùng tìm hiểu ứng dụng, thách thức trong bài toán này đồng thời mình cũng giới thiệu cho mọi người một thư viện do @SunAiResearchTeam đóng góp cho cộng đồng gần đây để giải quyết bài toán này.
II. Ứng dụng bài toán.
Mục tiêu của nhận diện cấu trúc văn bản là chuyển đổi thông tin bảng dưới dạng ảnh sang những định dạng văn bản có thể chỉnh sửa được. Qua đó giúp giảm thiểu công sức, thời gian của công việc lặp lại cho con người, dễ dàng quản lý, chỉnh sửa một cách dễ dàng. chúng ta có thể chia làm hai lọai theo mục đích sử dụng:
- Sử dụng cá nhân
- Sử dụng công nghiệp
1. Sử dụng cá nhân
 Ảnh minh họa (Nguồn internet)
Ảnh minh họa (Nguồn internet)
Nhận diện cấu trúc bảng giúp ích trong nhiều tác vụ đối với khách hàng là các cá nhân. Ví dụ thỉnh thoảng chúng ta chụp tài liệu bằng điện thoại di động và chúng ta phải sao chép tài liệu đó sang máy tính, đánh máy lại. Nếu sử dụng phương pháp trích xuất bảng chúng ta có thể dễ dàng lưu chúng sang các định dạng có thể chỉnh sửa mà vẫn giữ nguyên định dạng, cấu trúc của văn bản. Sau đây là một số trường hợp ứng dụng cá nhân của bài toán:
-
Scan tài liệu bằng điện thoại: Chúng ta thường chụp ảnh các dữ liệu bảng quan trọng bằng điện thoại và lưu giữ chúng. Nhưng với giải pháp trích xuất bảng, chúng ta có thể chụp ảnh và lưu trữ chúng dươi dạng các văn bản có thể chỉnh sửa như excel, google sheets,...Nhờ vậy chúng ta có thể dễ dàng tìm kiếm và sao chép nội dung bảng sang các văn bản khác hoặc chúng ta có thể dùng trực tiếp bảng đã được trích xuất.
-
Chuyển văn bản sang định dạng HTML: Khi muốn biểu diễn dữ liệu bảng lên một trang web, bây giờ chúng ta chỉ cần chụp ảnh hoặc đưa tập tin pdf vào, chúng ta chỉ cần thêm vài dòng code có thể số hóa các dữ liệu bảng đưa lên các trang web.
2. Sử dụng trong công nghiệp
Có rất nhiều công ty thuộc nhiều lĩnh vực đang phải xử lý với số lượng tài liệu khổng lồ đặc biệt là các lĩnh vực như ngân hàng và bảo hiểm. Từ việc lưu trữ thông tin của khách hàng đến chăm sóc nhu cầu của khách hàng, bảng đều được sử dụng vô cùng rộng rãi. Các tài liệu bản mềm (pdf, docx) được chuyển sang các dạng bản cứng truyền đi khắp các công ty do đó khó quản lý, thỉnh thoảng có khả năng gây mất mát thông tin. Bằng phương pháp trích xuất bảng, có thể dễ dàng tự động hóa số hóa bảng giảm thời gian và lỗi gặp phải.
-
Kiểm soát chất lượng: Kiểm soát chất lượng là một trong những dịch vụ cốt lõi của nhiều lĩnh vực. Các công ty thường dùng biểu mẫu dưới dạng bảng để thu thập phản hồi từ người tiêu dùng về dịch vụ được cung cấp hoặc các ghi chú về dây chuyền sản xuất đang hoạt động như thế nào ? Tất cả các biểu mẫu trên có thể dễ dàng được số hóa bằng cách sử dụng phương pháp trích xuất bảng.
-
Theo dõi hàng hóa: Trong công nghiệp, con người thường dùng bảng cứng để theo dõi các số lượng đơn vị hàng hóa như sắt, thép, ...Việc tự động hóa có thể giúp tiết kiệm rất nhiều thời gian quản lý và hạn chế tài sản bị thất thoát hoặc vấn đề không thống nhất dữ liệu.
III. Thư viện Table Reconstruction
1. Giới thiệu
Với mong muốn đóng góp thêm nhiều vào công cuộc quá trình số hóa dữ liệu quốc gia cũng như chia sẻ ý tưởng tới cộng đồng IT Việt Nam, Sun* AI Research Team chúng mình đã xây dựng tool Table Reconstruction.
Table Reconstruction là công cụ giúp trích xuất vùng bảng (nếu có) ở đầu vào và tái thiết kiến trúc bảng bằng cách sử dụng các mô hình học sâu và các thuật toán xử lý logic. Công cụ này đã được đội của mình đóng gói hoàn chỉnh và các bạn có thể dễ dàng cài đặt bằng một câu lệnh pip quen thuộc:
pip install table-reconstruction
Hoặc các bạn có thể cài đặt thủ công như sau:
git clone https://github.com/sun-asterisk-research/table_reconstruction.git
cd table_reconstruction
python setup.py install
2. Thuật toán và mô hình
Để tái cấu trúc lại bảng dựa trên ảnh đầu vào, chúng tôi đề xuất các bước xử lý chính như sau:
Bước 1: Xác định vùng chứa bảng
Bước 2: Phân đoạn lấy ra ảnh nhị phân chứa các vùng đường thẳng
Bước 3: Tái cấu trúc bằng thuật toán xử lý logic
2.1. Table Detection
2.1.1. Mô hình Yolov5
Trong quá trình phát triển package Table Reconstruction chúng tôi sử dụng mô hình Yolov5s cho bước xác định vùng chứa bảng. Giống như đa số các mô hình phát hiện đối tượng khác, các mô hình Yolov5 nhận đầu vào là một ảnh và kết quả trả ra là tọa độ của đối tượng trong ảnh đó (nếu có) cùng với đó là độ tự tin của dự đoán (confidence score).
Một số kết quả phát hiện vùng chứa bảng

2.1.2. Dữ liệu huấn luyện
Trong nghiên cứu thực hiện huấn luyện và thử nghiệm các mô hình phát hiện bảng chúng tôi sử dụng tập dữ liệu TableBank, chi tiết về tập dữ liệu này các bạn có thể tham khảo tại đây
Sơ qua một chút về TableBank, đây là tập dataset cung cấp dữ liệu phục vụ cho 2 nhiệm vụ chính là Table Detection và Table Recognition. Trong việc huấn luyện các mô hình phát hiện bảng thì nhóm phát triển chúng tôi chỉ quan tâm đến phần dữ liệu Table Detection. Phần dữ liệu Table Detection của tập dataset TableBank được xây dựng trên 2 loại định dạng văn bản là word và latex. Số lượng dữ liệu cho từng loại được thống kê như ở bảng dưới đây.
Thống kê dựa trên số lượng ảnh:
| Word | Latex | Word + Latex |
|---|---|---|
| 78,399 | 200,183 | 278,582 |
Thống kê dựa trên số lượng bảng:
| Word | Latex | Word + Latex |
|---|---|---|
| 163,417 | 253,817 | 417,234 |
Team chúng tôi sử dụng dữ liệu tổng của 2 loại Latex và Word để huấn luyện và đánh giá mô hình phát hiện bảng.
Thông số độ chính xác của mô hình Yolov5s sau quá trình huấn luyện trên tập dữ liệu TableBank
| Model | Precision | Recall | mAP 0.5 | mAP 0.5:0.95 |
|---|---|---|---|---|
| Yolov5s | 0.9819 | 0.9852 | 0.9931 | 0.9783 |
Thống kê số lượng ảnh của các tập Train/Val/Test:
| Source | Train | Val | Test |
|---|---|---|---|
| Latex | 187199 | 7265 | 5719 |
| Word | 73383 | 2735 | 2281 |
| Total | 260582 | 10000 | 8000 |
Kết quả khi predict 1 batch ảnh trong tập test khi sử dụng mô hình Yolov5s

2.2 Line Segmentation
2.2.1. Mô hình
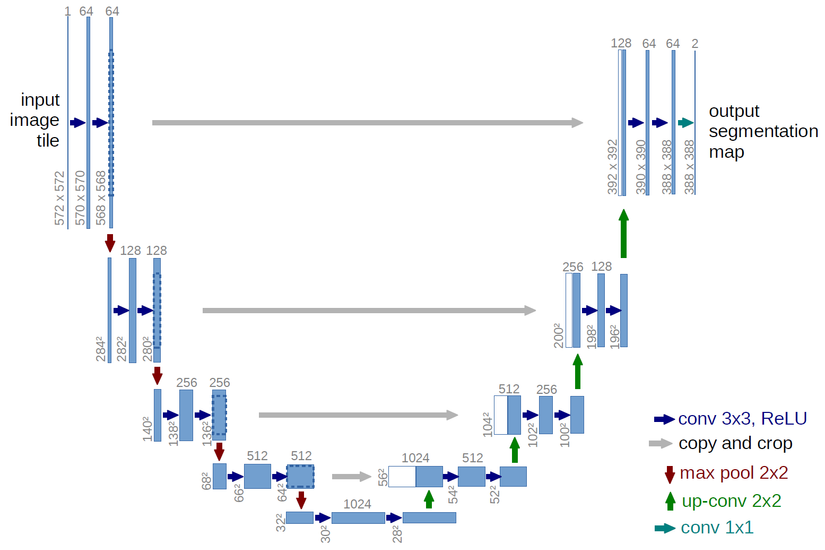 Mô hình Unet (Nguồn internet)
Mô hình Unet (Nguồn internet)
Phần mã hóa: gồm các lớp mạng tích chập không có các lớp FC có mục đích giảm kích thước ảnh đầu vào và trích xuất đặc trưng.
Phần giải mã: tùy vào kiến trúc mạng phần mã hóa mà ta có thể xây dựng khác nhau. Mục tiêu của phần giải mã là kết hợp đặc trưng của nhiều tầng khác nhau để tăng cường thông tin biểu diễn đồng thời để khôi phục lại kích thước giống như ảnh gốc.
Sau khi đi qua mô hình line segment chúng ta có kết quả:
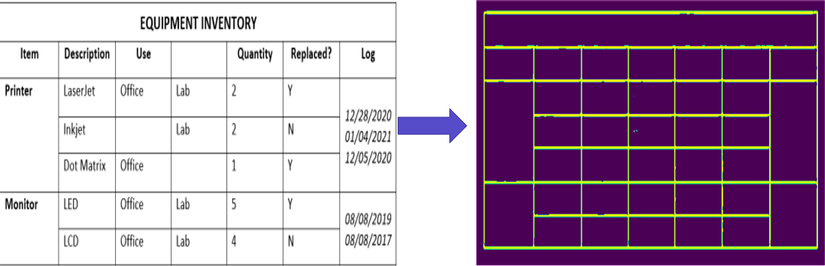 Kết quả sau khi đi qua mô hình Line Segmentation
Kết quả sau khi đi qua mô hình Line Segmentation
2.2.2. Dữ liệu
Trong nghiên cứu lần này, tôi sử dụng tập dữ liệu SciTSR bao gồm 15000 bảng ở định dạng PDF. Các bạn có thể tải bộ dữ liệu này ở đây: SciTSR.
| Train | Test | |
|---|---|---|
| bảng bình thường | 12000 | 3000 |
| bảng phức tạp | 2885 | 716 |
| tỉ lệ bảng phức tạp | 24% | 23.9% |
| tỉ lệ số hàng / bảng | 9.29 | 9.31 |
| tỉ lệ số cột / bảng | 5.21 | 5.18 |
| tỉ lệ số ô / bảng | 47.74 | 48.80 |
2.3.Tái cấu trúc bảng bằng thuật toán xử lý logic
2.3.1. Định nghĩa đồ thị
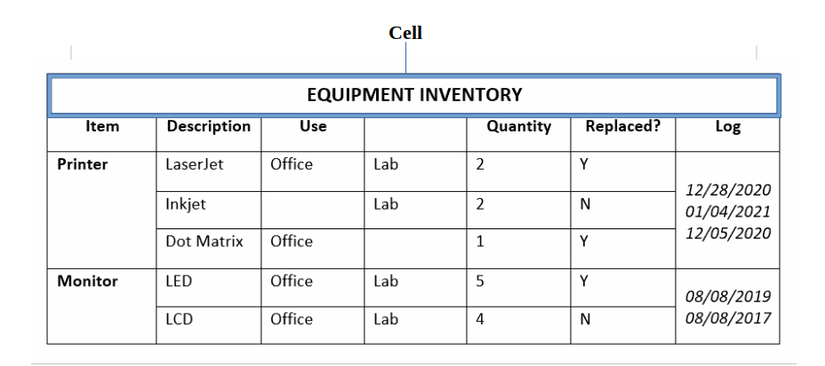 Ảnh minh họa cell
Ảnh minh họa cell
2.3.2. Trích xuất tọa độ của các ô.
Do một đỉnh ở đây là một ô nên từ ảnh mask đầu vào chúng tôi thực hiện dùng các thuật toán để tính ra được tọa độ các ô làm đầu vào cho đồ thị vô hướng bên dưới.
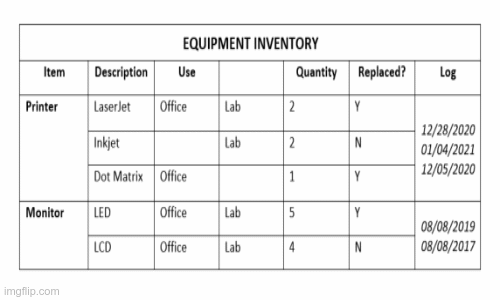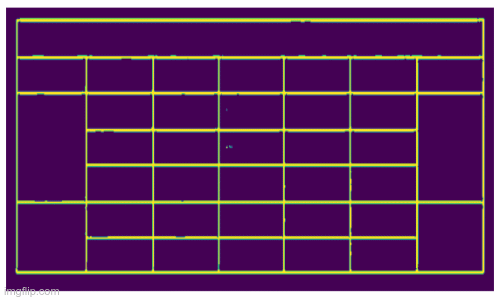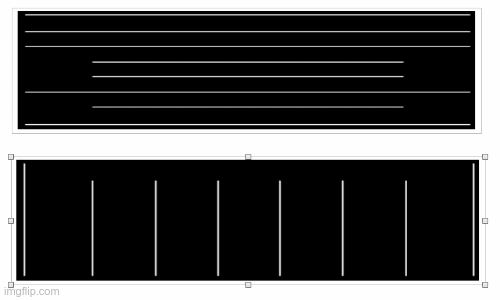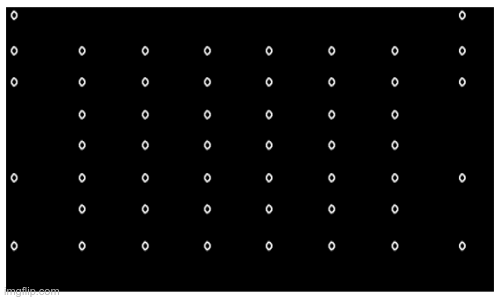 Mô phỏng các bước xử lý
Mô phỏng các bước xử lý
2.3.3. Xây dựng đồ thị và tái cấu trúc bảng

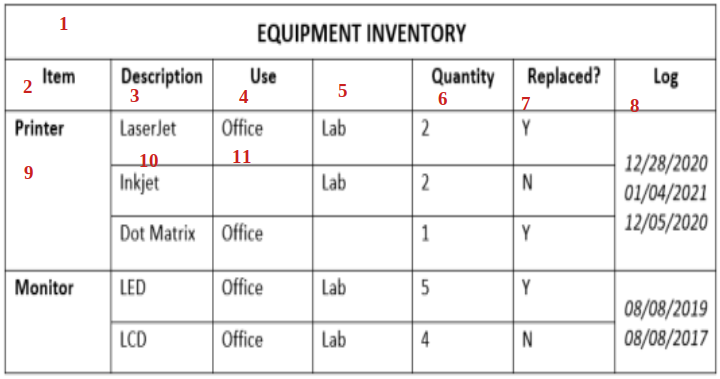
Sau khi trích xuất được tọa độ các ô, các ô sẽ được sắp xếp theo thứ tự từ trái sang phải, từ trên xuống dưới được minh họa như hình bên trên. Sau đó ta xây dựng 2 đồ thị vô hướng tương ứng các ô liên kết theo chiều dọc và các ô liên kết theo chiều ngang. Từ đó ta tính ra được số cột, số hàng của bảng và tọa độ các ô đặc biệt như "span cell". Cuối cùng ta có đầy đủ thông tin cần thiết để tái cấu trúc bảng.
IV. Lời cảm ơn
Cảm ơn mọi người đã theo dõi bài viết cũng như thư viện Table Reconstruction. Hiện tại thư viện mới ra mắt bản đầu tiên cũng khó có thể tránh khỏi việc chưa thiện và còn nhiều sai sót. Hy vọng được các bạn ủng hộ và có nhiều đóng góp phát triển dự án hoàn thiện hơn nữa. Chúng tôi cũng đang phát triển một bản dùng trong mục đích thương mại, khách hàng nào quan tâm hoặc đóng góp tới dự án chúng tôi có thể liên qua mail [email protected]. Chúng tôi rất hân hạnh khi được hợp tác cùng mọi người.
Tài liệu liên quan
- Katharina Kaiser Burcu Yildiz and Silvia Miksch. pdf2table: A method to extract table information from pdf files., 2005.
- Shaoqing Ren Kaiming He, Xiangyu Zhang and Jian Sun. Deep residual learning for image recognition ., 2015.
- Philipp Fischer Olaf Ronneberger and Thomas Brox. U-net: Convolu- tional networks for biomedical image segmentation ., 2015.
- S. Schreiber, S. Agne, I. Wolf, A. Dengel, and S. Ahmed. Deepdesrt: Deep learning for detection and structure recognition of tables in docu- ment images. In 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), volume 01, pages 1162–1167, 2017.
- Karen Simonyan and Andrew Zisserman. An approach for recognizing and extracting tables from pdf documents., 2015.
- Minghao Li1 , Lei Cui2 , Shaohan Huang2 , Furu Wei2 , Ming Zhou2 , Zhoujun Li1. TableBank: A Benchmark Dataset for Table Detection and Recognition
- Dataset SciTSR
- Dataset Table Bank
- Github yolov5