Ở bài viết trước mình đã cùng các bạn tạo tìm hiểu về các module của thư viện face-api.js và cùng làm một app về khả năng nhận diện khuôn mặt. Bài viết hôm này mình sẽ sử dụng tiếp thư viện face-api.js để làm một app giúp chúng ta hiểu rõ hơn về khả năng phát hiện khuôn mặt của thư viện face-api.js
Về project này thì mình sẽ stream video thông qua webcam của laptop để có thể lấy được hình ảnh của bạn. Sau đó áp dụng face-api.js để có thể phát hiện được khuôn mặt của bạn, hiện xem cảm xúc của bạn đang như thế nào(bất ngờ, vui vẻ, bình thường...). hiện các điểm nhận dạng trên mặt nữa
Bắt đầu với việc thêm các module của face-api.js vào project
Vẫn sẽ là những thư mục thân quen như là models và face-api.min.js các bạn có thể đọc lại bài biết để xem cách lấy các file như thế nào.
Ở trong file index thì chúng ta sẽ thêm nội dung html phù hợp như sau
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Face detection</title>
<script defer src="face-api.min.js"></script>
<script defer src="script.js"></script>
<style>
body {
margin: 0;
padding: 0;
width: 100vw;
height: 100vh;
display: flex;
justify-content: center;
align-items: center;
}
canvas {
position: absolute
}
</style>
</head>
<body>
<video id="video" width="720" height="560" autoplay muted></video>
</body>
</html>
Ở trong file script các bạn thêm code
const video = document.getElementById('video');
Promise.all([
faceapi.nets.tinyFaceDetector.loadFromUri('/models'),
faceapi.nets.faceLandmark68Net.loadFromUri('/models'),
faceapi.nets.faceRecognitionNet.loadFromUri('/models'),
faceapi.nets.faceExpressionNet.loadFromUri('/models')
]).then(startVideo)
function startVideo() {
navigator.getUserMedia(
{video: {}},
stream => video.srcObject = stream,
err => console.error(err)
)
}
Sau khi thêm code này bạn kiểm tra xem đã nhận webcam hay chưa và mình tải các module lên trước là có dụng ý vì các bạn phải tải trước các module trước khi bật cam thì mới có thể sử dụng được thành quả sẽ được như thế này(mình lấy con gấu che đi thôi nha). Hai module mới mà chúng ta sử dụng ngày hôm nay là faceRecognitionNet dùng để phát hiện các khuôn mặt và faceExpressionNet dùng để phát hiện những biểu cảm trên khuôn mặt.

Tiếp theo chúng ta sẽ bắt sự kiện khi mà cam chạy rồi sử dụng các hàm được cung cấp để phát hiện khuôn mặt cũng như xuất các thông tin cần thiết lên màn hình:
video.addEventListener('play', () => {
const canvas = faceapi.createCanvasFromMedia(video)
document.body.append(canvas)
const displaySize = {width: video.width, height: video.height}
faceapi.matchDimensions(canvas, displaySize)
setInterval(async () => {
const detections = await faceapi.detectAllFaces(video, new faceapi.TinyFaceDetectorOptions()).withFaceLandmarks().withFaceExpressions()
const resizedDetections = faceapi.resizeResults(detections, displaySize)
canvas.getContext('2d').clearRect(0, 0, canvas.width, canvas.height)
faceapi.draw.drawDetections(canvas, resizedDetections)
faceapi.draw.drawFaceLandmarks(canvas, resizedDetections)
faceapi.draw.drawFaceExpressions(canvas, resizedDetections)
}, 100)
})
Ở đây chúng ta gọi hàm setInterval với độ trễ là 100ms để có thể luôn lặp lại các thao tác này bên trong sẽ là một hàm bất đồng bộ const detections = await faceapi.detectAllFaces(video, new faceapi.TinyFaceDetectorOptions()).withFaceLandmarks().withFaceExpressions() ở đây chúng ta gọi faceapi và hàm detectAllFaces với tham số là video để biết lấy khuôn mặt từ đâu và faceapi.TinyFaceDetectorOptions() là các option chúng ta có thể thêm vào để nhưng ở đây chúng ta không truyền thêm tham số gì cả vì như này cũng đã đủ để sử dụng. Bên ngoài thì chúng ta tiếp tục sử dụng các hàm như withFaceLandmarks để hiển thị các điểm nhận diện trên khuôn mặt, withFaceExpressions để nhận diện các biểu cảm trên khuôn mặt đấy.
Tiếp theo để hiển thị các kết quả lên màn hình chúng ta sẽ thêm hộp canvas vào đầu tiên là tạo nó bằng faceapi.createCanvasFromMedia(video) sau đó append vào body, sau khi đã tạo được canvas rồi thì chúng ta phải cho nó biết chỗ cần phải xuất hiện. Chúng ta sẽ định nghĩa một biến để lưu thông tin chiều cao và chiều rộng của thẻ videos const displaySize = {width: video.width, height: video.height} Tiếp theo chúng ta gọi const resizedDetections = faceapi.resizeResults(detections, displaySize) để thực hiện việc reszie lại mỗi khung hình khi nhận thấy có khuôn mặt và thực hiện vẽ hộp canvas bằng faceapi.draw.drawDetections(canvas, resizedDetections) nhưng nếu chỉ như thế này bạn sẽ gặp lỗi hiển thị vì cứ mỗi khung hình sẽ vẽ một hộp canvas lên và chúng bị trận lên nhau nên chúng ta sẽ thực hiện viêc xóa đi hộp canvas ở mỗi lần gọi lại bằng cách canvas.getContext('2d').clearRect(0, 0, canvas.width, canvas.height). Cuối cùng là chúng ta chỉ cần hiển thị thêm thông tin trên hộp canvas bằng cách
faceapi.draw.drawFaceLandmarks(canvas, resizedDetections)
faceapi.draw.drawFaceExpressions(canvas, resizedDetections) nữa là xong. Kết quả chúng ta thu được là
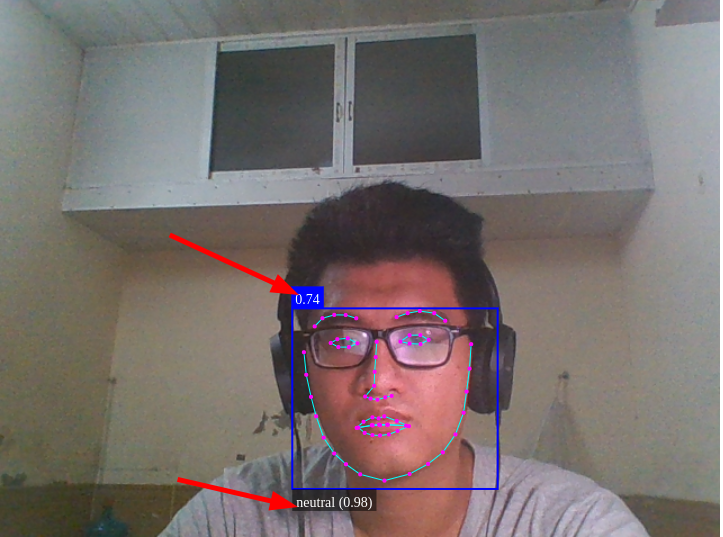
Chúng ta có thể thấy được tỉ lệ chính xác nhận dạng khuôn mặt và tỉ lệ chính xác cảm xúc hiện tại.