Đây là một bài trong series Báo khoa học trong vòng 5 phút.
Nguồn
Được viết bởi Chen et. al, IBM. Được đăng ở AAAI '18.
https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/viewFile/16893/15665
Ý tưởng chính
Thay vì sử dụng như Carlini-Wagner (CW), hay như PGD, thì tác giả sử dụng kết hợp giữa và tương tự với Elastic-Net Regularization. Cụ thể, mục đích tối thượng là tối ưu hàm loss sau:
trong đó được định nghĩa là độ thành công của tấn công, với giá trị bé hơn 0 là thành công, và ngược lại. Công thức của cho targeted attack tới class là
với Logit là giá trị vector ngay trước softmax, là độ "an toàn" của tấn công, còn phiên bản untargeted với true label là
càng tăng thì độ an toàn của tấn công càng lớn, và các adversarial example này sẽ càng có khả năng transfer — chúng có thể được sử dụng trên một model khác train cùng task cùng data.
Sau đó, tác giả tối ưu hóa hàm này bằng FISTA (phiên bản nhanh hơn của ISTA, mà không sử dụng SGD). Thay vì tối ưu cả hàm phức tạp, chúng ta chỉ tối ưu hàm không có term -norm
và sử dụng projected shrinkage-thresholding:
Về cơ bản, nếu thay đổi không lớn hơn ngưỡng , chúng ta giữ giá trị ban đầu, còn nếu lớn hơn chúng ta chọn một giá trị gần ảnh gốc nhưng vẫn trong khoảng cho đúng domain của ảnh.
Thuật toán đầy đủ của phương pháp EAD như sau:
- Với ảnh đầu vào là , khởi tạo
- Với số lần chạy FISTA là , chúng ta update các giá trị trên lần theo công thức:
với là step size cho từng iteration.
- Cuối cùng, check giá trị của các iteration xem có cái nào tấn công thành công không.
Phần sử dụng chính là cải tiến của FISTA từ thuật toán gốc ISTA.
Kết quả cho thấy tấn công này với có tỉ lệ thành công cao (100%!), ngang ngửa với CW và I-FGM (còn có tên là BIM — đây là phiên bản tiền thân của PGD, click vào link này để biết thêm chi tiết). Trong đó, CW cho khoảng cách bé nhất, I-FGM- cho khoảng cách bé nhất, và EAD cho khoảng cách bé nhất. Ngoài ra, các adversarial của EAD nhìn có vẻ giống với ảnh gốc nhất.

Còn với , độ thành công giảm xuống, tuy nhiên transferability tăng; có nghĩa là adversarial example được sinh ra cho 1 model có thể sử dụng với model khác, bao gồm cả các model được train bằng defensive distillation[1]. Tuy nhiên, nếu tăng quá cao thì các adversarial example sẽ không còn nằm trong data domain nữa (mà overfit vào model), nên transferability lại giảm xuống.
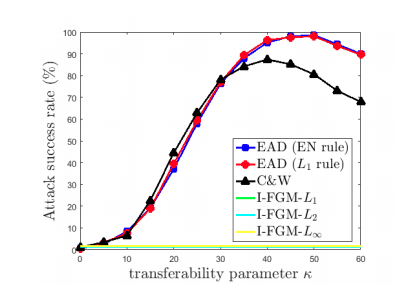
[1] Defensive distillation là khi sử dụng distillation để dạy cho một mô hình bé hơn bằng adversarial data và soft label của mô hình lớn hơn, dùng để giảm kích cỡ mô hình đồng thời tăng khả năng phòng chống tấn công.
Phần còn lại của paper
Khi thì EAD trở thành CW, nên có thể coi EAD là phiên bản mở rộng của CW. Đó cũng là lý do tại sao các adversarial example của EAD có độ khác nhau bé hơn CW, nhưng lớn hơn.
Tác giả không sử dụng Change-of-Variable (phương pháp được sử dụng trong CW để ép adversarial example trong khoảng (0,1)) do không phù hợp với objective trong hàm , vì vậy nên phải sử dụng FISTA thay vì SGD.
Nếu sử dụng tấn công này với adversarial training thì model lại càng tốt.
Bình luận
Tác giả cho rằng MNIST là data khó tấn công nhất do ảnh tập này sửa tí là dễ nhận ra, tuy nhiên cần nhận thấy là dataset này quá đơn giản, khiến cho việc tạo ra adversarial lại rất dễ.
Có thể việc phương pháp này tốt hơn là do thêm các regularization terms khác cho adversarial example nhìn giống ảnh gốc hơn. Vậy nếu chúng ta thêm các norm khác thì sao?
Hết.
Hãy like subscribe và comment vì nó miễn phí?