Giới thiệu
Chào các bạn tới với series về kubernetes. Đây là bài thứ 16 trong series của mình, ở bài trước chúng ta đã nói về cách quản lý tài nguyên của Pod trên cluster chúng ta như thế nào là hiệu quả nhất, ở bài này chúng ta sẽ nói về một chủ đề mà mình thấy là thú vị nhất, đó là autoscaling Pod và cluster.
Nói về scale thì có 2 cách scale là horizontal scaling và vertical scaling:
- Horizontal scaling là cách scale mà ta sẽ tăng số lượng worker (application) đang sử lý công việc hiện tại ra nhiều hơn. Ví dụ ta đang 2 Pod để xử lý tích điểm cho client khi client tạo deal thành công, khi số lượng client tăng đột biến, 2 Pod hiện tại không thể xử lý kịp, ta sẽ scale số lượng Pod lên thành 4 Pod chẳng hạn.
- Vertical scaling là cách scale thay vì tăng số lượng worker lên, ta sẽ tăng số lượng tài nguyên có thể sử dụng của ứng dụng đó lên, như là tăng số lượng cpu và memory của ứng dụng đó. Ví dụ ta có một model để train AI, thì việc train AI này ta không thể tách ra một model khác để tăng tốc độ train được, mà ta chỉ có thể tăng cpu và memory cho model đó.
Trong kubernetes, ta horizontal scale bằng cách tăng số lượng ở thuộc tính replicas của ReplicationController, ReplicaSet, Deployment. Vertical scale bằng cách tăng resource requests và limits của Pod. Ta có thể làm việc này bằng tay, nhưng sẽ gặp rất nhiều bất lợi, ta không thể ngồi cả ngày để kiểm tra lúc nào ứng dụng của ta có nhiều client sử dụng nhất để ta kết nối lên kubernetes cluster rồi gõ câu lệnh để scale được, mà ta muốn công việc này có thể tự động cho ta.
Kubernetes có cung cấp cho chúng ta cách autoscaling dựa vào việc phát hiện cpu hoặc memory ta chỉ định đã đạt tới ngưỡng scale. Nếu ta xài cloud, nó còn có thể tự động tạo thêm worker node khi phát hiện không còn đủ node cho Pod deploy.
Horizontal pod autoscaling
Horizontal pod autoscaling là cách scale số lượng của pod replicas ở trong các scalable resource (Deployment, ReplicaSet, ReplicationController, or StatefulSet). Công việc này được thực hiện bởi Horizontal controller khi ta tạo một HorizontalPodAutoscaler (HPA) resource. Horizontal controller sẽ thường xuyên kiểm tra metric của Pod, và tính toán số lượng pod replicas phù hợp dựa vào metric kiểm tra của Pod hiện tại với giá trị metric mà ta đã chỉ định ở trong HPA resource, sau đó sẽ thay đổi trường replicas của các scalable resource (Deployment, ReplicaSet, ReplicationController, or StatefulSet) nếu nó thấy cần thiết.
Ví dụ file config của một HPA sẽ như sau:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: micro-services-autoscale
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: microservice-user-products
minReplicas: 2
maxReplicas: 5
metrics:
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 70
Ở file trên, ta chỉ định scalable resource bằng thuộc tính scaleTargetRef, ta chọn resource ta muốn scale là Deployment và tên của Deployment đó, ta chỉ định số lượng min và max replicas bằng 2 thuộc tính minReplicas, maxReplicas. Metric mà ta muốn thu thập là memory, với giá trị sử dụng là 70%. Khi pod metric thu thập vượt qua giá trị này, quá trình autoscaling sẽ được thực thi.
Quá trình Autoscaling
Quá trình autoscaling được chia thành 3 giao đoạn như sau:
- Thu thập metrics của tất cả các Pod được quản lý bởi scalable resource mà ta chỉ định trong HPA.
- Tính toàn số lượng Pod cần thiết dựa vào metrics thu thập được.
- Cập nhật lại trường replicas của scalable resource.
Thu thập metrics
Horizontal controller sẽ không trực tiếp thu thập metrics của Pod, mà nó sẽ lấy thông qua một thằng khác, được gọi là metrics server. Ở trên từng worker node, sẽ có một thằng được gọi là cAdvisor, đây là một component của kubelet, có nhiệm vụ thu thập metric của Pod và node, sau đó những metric này sẽ được tổng hợp ở metrics server, và thằng horizontal controller sẽ lấy metric từ metrics server ra.
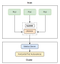
Ta cần lưu ý một điều ở đây là thằng metrics server này là một add-ons, chứ nó không có sẵn trong kubernetes cluster của ta, nếu ta muốn sử dụng được tính năng autoscaling, ta cần phải cài metrics server này vào. Cách cài thì các bạn xem ở đây https://github.com/kubernetes-sigs/metrics-server.
Tính toàn số lượng Pod cần thiết
Sau khi horizontal controller thu thập được metric, nó sẽ tiến hành giai đoạn tiếp theo là tính toàn số lượng Pod dựa theo metric thu thập được với số metric ta chỉ định trong HPA, nó sẽ tính ra số replicas mà từ hai thằng metric ở trên theo một công thức có sẵn. Với giá trị đầu vào là một nhóm pod metrics và đầu ra là số replicas tương ứng. Công thức dạng đơn giản như sau:
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
Cấu hình chỉ có một metric
Khi một HPA cấu hình chỉ có một metric (chỉ có cpu hoặc memory) thì việc tính toán số lượng Pod chỉ có một bước là sử dụng công thức trên. Ví dụ ta có giá trị current metric hiện tại là 200m, giá trị desired là 100m, current replicas là 2, ta sẽ có:
currentMetricValue / desiredMetricValue = 200m / 100m = 2
desiredReplicas = ceil[2 * (2)] = 4
Số lượng replicas của ta bây giờ sẽ được scale từ 2 lên 4. Một ví dụ khác là ta có giá trị current metric hiện tại là 50m, , giá trị desired là 100m, ta sẽ có:
currentMetricValue / desiredMetricValue = 50m / 100m = 0.5
Horizontal controller sẽ bỏ qua việc scale khi giá trị của currentMetricValue / desiredMetricValue xấp xỉ 1.
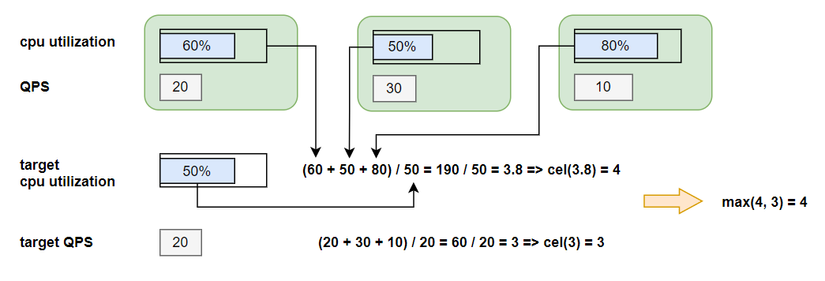
Cấu hình nhiều metric
Khi HPA của ta cấu hình mà có nhiều metric (có cpu và Queries-Per-Second), thì việc tính toán cũng không phức tạp hơn lắm, horizontal controller sẽ tính ra giá trị replicas của từng thằng metric riêng lẽ, sau đó sẽ lấy giá trị replicas lớn nhất.
max([metric_one, metric_two, ...n])
Ví dụ, ta có số replicas sau khi tính ra của cpu là 4, của Queries-Per-Second là 3, thì max(4, 3) = 4, số lượng replicas sẽ được scale lên là 4.

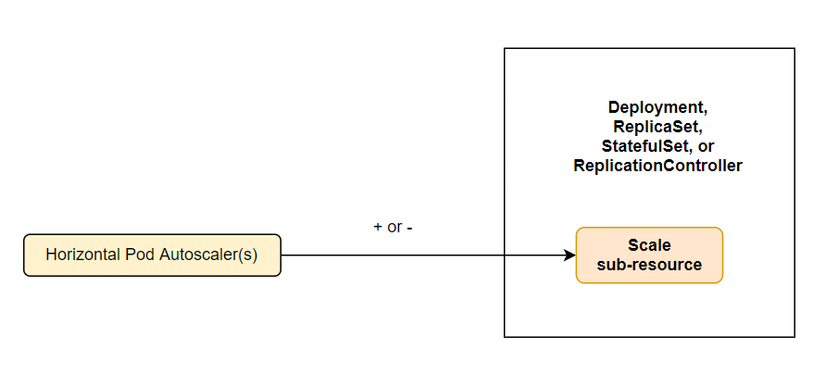
Cập nhật trường replicas
Đây là bước cuối cùng của quá trình autoscaling, horizontal controller sẽ cập nhật lại giá trị replicas của resoucre ta chỉ định trong HPA, và để resoucre đó tự động thực hiện việc tăng số lượng Pod hoặc giảm số lượng Pod. Hiện tại thì autoscaling chỉ hỗ trợ các resource sau đây:
- Deployments
- ReplicaSets
- ReplicationControllers
- StatefulSets

Bây giờ chúng ta sẽ làm thực hành để hiểu rõ hơn về quá trình autoscaling này.
Scale theo CPU sử dụng
Giờ ta sẽ tạo một deployment, và một HPA với cấu hình metric là số lượng CPU sử dụng. Lưu ý một điều nữa là khi khai báo resource muốn autoscaling được, ta phải chỉ định trường resource request cho nó, nếu không thì resource của chúng ta sẽ không thể scale được, vì nó không có ngưỡng nào để tính được desired metric cả.
Tạo một file deployment.yaml với config như sau:
apiVersion: apps/v1
kind: Deployment
metadata:
name: kubia
spec:
replicas: 3
selector:
matchLabels:
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- image: luksa/kubia:v1
name: nodejs
resources:
requests:
cpu: 100m
Ở file config trên, ta tạo Deployment với số lượng replicas là 3, và cpu requests là 100m. Giờ ta sẽ tạo HPA, tạo một file tên là hpa.yaml với config như sau:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: kubia
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: kubia
minReplicas: 1
maxReplicas: 5
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 30
Tạo và kiểm tra thử:
$ kubectl apply -f deployment.yaml
deployment.apps/kubia created
$ kubectl apply -f hpa.yaml
horizontalpodautoscaler.autoscaling/kubia created
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
kubia Deployment/kubia <unknown>/30% 1 5 3 88s
Nếu bạn get hpa ra và thấy thông tin target metric là <unknown>/30%, thì ta sẽ chờ một chút để cAdvisor thu thập được dữ liệu.
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
kubia Deployment/kubia 0%/30% 1 5 1 8m29s
Khi ta get hpa lại, nếu trường target meritc là 0%/30% thì cAdvisor đã report dữ liệu lên metrics server, và horizontal controller đã lấy được dữ liệu từ trên metrics server. Bạn có để ý là ở trường REPLICAS của ta chỉ có 1 replicas không, khi nãy ta tạo deployment là 3 replicas mà, sao bây giờ chỉ có 1 vậy? Ta get deployment ra xem sao.
$ kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
kubia 1/1 1 1 12m
Ta cũng sẽ thấy là chỉ có 1 Pod ở deployment mà thôi, là do bây giờ Pod của chúng ta không sử dụng bất kì CPU nào cả, nên HPA thu thập metric và thấy số lượng replicas cần là 0, nên nó scale down số lượng Pod xuống để tránh gây lãng phí tài nguyên của node, nhưng vì ta có chỉ định trương minReplicas là 1, nên số lượng Pod của chúng ta mới còn lại là 1 Pod.
Trigger scale up
Ta đã thấy scale down đã hoạt động đúng, giờ ta sẽ xem scale up sẽ hoạt động như thế nào. Trước tiên ta cần expose traffic để cho client có thể gọi vào Pod được tạo thông qua Deployment ở trên.
$ kubectl expose deployment kubia --port=80 --target-port=8080
service/kubia exposed
Ta chạy câu lệnh sau để xem rõ quá trình scale up của một resource.
$ watch -n 1 kubectl get hpa,deployment
Every 1.0s: kubectl get hpa,deployment LAPTOP-2COB82RG: Tue Nov 2 16:39:07 2021
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/kubia Deployment/kubia 0%/30% 1 5 1 22m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kubia 1/1 1 1 22m
Mở một terrminal khác.
$ kubectl run -it --rm --restart=Never loadgenerator --image=busybox -- sh -c "while true; do wget -O - -q http://kubia; done"
Sau khi chạy câu lệnh trên xong, quay lại terrmail ta chạy câu lệnh watch khi nãy, ta sẽ thấy số lượng cpu sẽ tăng lên, và theo đó, số lượng replicas của Deployment cũng sẽ được scale up lên theo.
Every 1.0s: kubectl get hpa,deployment LAPTOP-2COB82RG: Tue Nov 2 16:45:27 2021
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/kubia Deployment/kubia 294%/30% 1 4 4 28m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kubia 4/4 4 4 29m
Khi ta describe hpa, ta sẽ thấy quá trình scale lên cộng với message scale lên bao nhiêu.
$ kubectl describe hpa
...
Normal SuccessfulRescale 5m19s horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target
Bạn sẽ để ý một điều là ở đây target metric là 294%, vậy theo công thực ở trên thì 294/30 = 9.8, ceil(9.8) phải bằng 10 chứ, sao số lượng scale lên chỉ có 4 replicas vậy?
Maximun rate of scaling
Ở trên, đáng lẻ ta sclae tới 10 replicas, nhưng ta chỉ scale lên tới 4 replicas vì mỗi lần scale, ta có số lượng giới hạn replicas có thể scale trong 1 lần. Mỗi lần scale, số lượng replicas tối ta có thể scale là gấp 2 lần số lượng replicas hiện tại, còn nếu số lượng replicas hiện tại là 1 hoặc 2, thì tối đa replicas sẽ được scale là 4 replicas.
Ví dụ hiện tại ta có số lượng Pod là 1, khi scale up được trigger, số lượng Pod tối đa có thể scale lên là 4, và khi số lượng Pod đã là 4, thì ở lần scale up sau, số lượng Pod tối đa có thể scale lên la 8. Cứ như vậy gấp 2 lên.
Và mỗi lần scale up thì ta cũng có thời gian giữa các lần với nhau, đối với scale up thì mỗi lần scale xong thì 3 phút sau nó mới trigger scale tiếp, còn đổi với scale down thì là 5 phút. Nếu bạn thấy số lượng target metric của ta đã vượt quá desired metric rồi mà sao quá trình scale chưa được trigger thì câu trả lời là vẫn chưa tới thời gian nó có thể trigger được.
Scale theo memory
Ta thấy là việc scale dựa theo cpu sử dụng rất dễ dàng, ta cũng có thể config để scale theo memory sử dụng, ta chỉ cần đổi giá trị cpu thành memory khi config, như sau:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: kubia
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: kubia
minReplicas: 1
maxReplicas: 5
metrics:
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 60
Nhưng ta cần lưu ý là scale dựa trên memory sẽ gặp nhiều vấn đề hơn scale dựa vào cpu, vì việc release và sử dụng memory sẽ phụ thuộc vào ứng dụng ở bên trong container. Khi ta scale up số lượng Pod lên dựa vào memory, system không thể chắc chắn được rằng số lượng sử dụng memory của từng ứng dụng sẽ giảm đi, vì điều này phụ thuộc vào cách ta viết ứng dụng, nếu sau khi ta scale up Pod lên, ứng dụng ta vẫn xài memory nhiều như trước, thì quá trình scale up này sẽ lập đi lập lại và đạt tới ngưỡng maximun Pod của một worker node, và có thể làm worker node die. Vì vậy nên khi scale Pod dựa vào memory ta cần phải xem xét nhiều yếu tố hơn chứ không phải chỉ cần config HPA là được.
Scale theo các metric khác
Ngoài cpu và memory, kubernetes cũng có hỗ trợ một số metric khác mà ta cũng hay cần xài, ở trên ta đã xài type Resource với cpu và memory, còn có 2 type khác nữa là Pods và Object.
Pod metric type thì gồm những metric nào liên quan tới Pod, 2 thằng hay xài là QueriesPer-Second và number of messages in a message broker’s queue (nếu ta xài message broker). Ví dụ như sau:
...
metrics:
- type: Pods
resource:
metricName: qps
targetAverageValue: 100
Object metric là những metric mà không liên quan trực tiếp tới Pod, mà sẽ liên quan tới những resource khác của cluster. Ví dụ như ingress:
...
type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
name: main-route
target:
type: Value
value: 2k
Ở trên ta chỉ định metric sẽ scale số lượng replicas dựa theo request tới ingress controller.
Scaling down to zero replicas
Hiện tại thì HPA không cho phép ta chỉ định trường minReplicas xuống là 0, kể cả khi Pod ta không xài tài nguyên nào cả, thì số lượng Pod ít nhất vẫn là 1. Vì scale số lượng replicas xuống 0 không phải là cách hay, vì ở lần request đầu tiên, ta sẽ không có Pod nào để xử lý cho client cả, và quá trình khởi tạo lần đầu này rất mất thời gian.
Vertical pod autoscaling
Ta đã thấy horizontal scaling giúp ta giải quyết được nhiều vần đề performance của ứng dụng, nhưng không phải ứng dụng nào ta cũng có thể scale theo kiểu horizontal được, ví dụ như model AI ta đã nói ở trên, mà ta cần scale theo kiểu vertical, tăng tài nguyên sử dụng của Pod.
Ta cần lưu ý là hiện tại khi mình viết bài này, kubernetes không có hỗ trợ resource Vertical có sẵn, mà nó cũng là một add-ons, ta cần phải cài vào thì mới có thể xài được. Cách cài VerticalPodAutoscaler ở đây https://github.com/kubernetes/autoscaler/tree/master/vertical-pod-autoscaler.
Ví dụ của file cấu hình VerticalPodAutoscaler như sau:
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: my-app-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: my-app
updatePolicy:
updateMode: "Auto"
Với targetRef ta sẽ chọn resoruce ta thu thập metric để scale, và updatePolicy.updateMode, ta sẽ có 3 mode là Off, Initial và Auto.
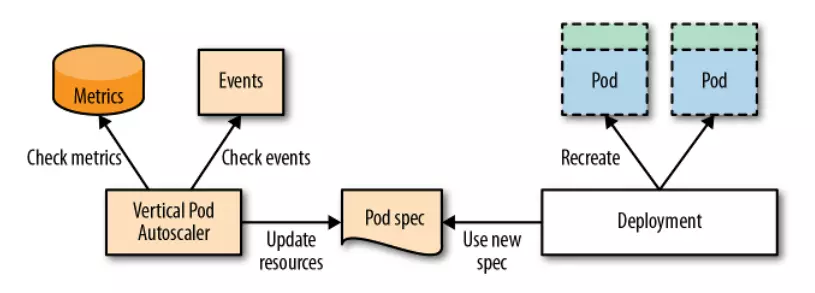
VPA component
VPA sẽ có 3 component như sau:
- Recommender: component này sẽ monitor các tài nguyên đã tiêu thụ trước đó tài nguyên hiện tại để cung cấp giá trị cpu và memory requests gợi ý.
- Updater: component này sẽ kiểm tra Pod được quản lý bởi scalable resource có cpu và memory đúng với giá trị của Recommender cung cấp ở trên hay không, nếu không, nó sẽ kill Pod đó và tạo lại Pod mới với cpu và memory requests đã được cập nhật đúng theo Recommender.
- Admission Plugin: đây là admission plugin của VPA thêm vào các Admission Plugin có sẵn của API server, có nhiệm vụ sẽ thay đổi resource requests của Pod khi nó được tạo để đúng với giá trị của Recommender.
Update Policy
Policy này sẽ điều kiển cách VPA áp dụng thay đổi lên cho Pod, được chỉ định thông qua thuộc tính updatePolicy.updateMode. Có 3 giá trị là:
- Off: Ở mode này, VPA chỉ tạo ra một recommendations, mà không áp dụng giá trị recommendations đó lên Pod, ta chọn mode này khi chỉ muốn xem giá trị requests được gợi ý cho chúng ta, và ta sẽ quyết định xem có cập nhật lại cpu và memory requests giống với giá trị gợi ý cho ta hay không.
- Initial: ở mode này, sau khi recommendations được tạo ra, thì chỉ những Pod nào được tạo mới sau khi có giá này recommendations này, thì mới áp dụng giá trị cpu và memory requests được gợi ý, những Pod hiện tại vẫn như cũ.
- Auto: ở mode này, sau khi recommendations được tạo ra, thì không những chỉ những Pod mới được áp dụng giá trị gợi ý này, mà kể cả những Pod hiện tại mà có giá trị không đúng với giá trị của recommendations, thì nó cũng sẽ bị restart lại.
Cluster Autoscaler
Ta đã thấy Horizontal Pod Autoscaling và Vertical Pod Autoscaling rất hữu dụng, nhưng khi ta gặp vấn đề là ta scale tới mức độ mà không còn node cho ta có thể scale nữa thì sao? Tất nhiên lúc này ta chỉ có thể scale bằng cách tạo thêm worker node và cho nó join vào master node. Khi ta chạy trên cloud, ta có thể config quá trình này tự động. Khi Pod ta được tạo ra mà không có node nào có thể chứa nó được nữa, Cluster Autoscaler này sẽ tự động tạo thêm node cho chúng ta.

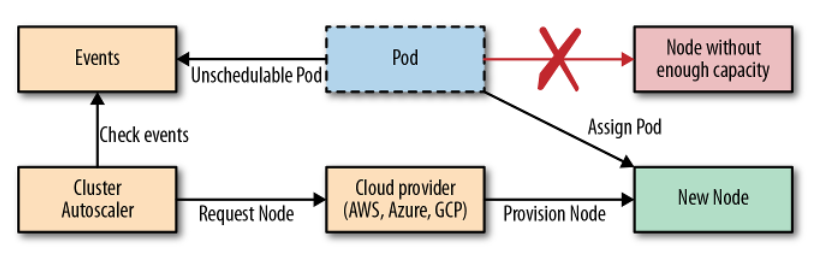
Và khi đó, Pod mà trước đó không thể schedule được của chúng ta sẽ được deploy tới worker node mới này. Đó là quá trình scale up, vậy còn scale down thì sao? Ta đâu thể để worker node chạy hoài khi mà ta không cần Pod chạy trên nó, vì xài cloud rất chi là tốn tiền. Quá trình scale down này sẽ phúc tạp hơn một xíu, Cluster Autoscaler sẽ scale down một node khi:
- Nhiều hơn một nửa capacity không được sử dụng, cộng tất cả request CPU và memory của Pod lại, nếu nhỏ hơn 50% là đúng với yêu cầu này.
- Tất cả các Pod hiện tại của node đó, có thể được di chuyên qua node khác mà không gặp vấn đề gì.
- Không có gì có thể ngăn chặn việc node đó bị xóa đi.
- Không còn Pod nào mà không thể di chuyển còn ở trên node đó.
Nếu tất cả các điều kiện trên đều là giá trị true, mặc định là trong khoảng 10 phút, thì node đó sẽ bị xóa đi khỏi kubernetes cluster. Quá trình xóa này gồm 2 bước, đầu tiên CA sẽ đánh dấu là node đó là unschedulable và move toàn bộ pod qua node khác, tương tự câu lệnh kubectl drain <node>, và sau đó node sẽ bị xóa đi.
CA được hỗ trợ bởi:
- Google Kubernetes Engine (GKE)
- Google Compute Engine (GCE)
- Amazon Web Services (AWS)
- Microsoft Azure
Với GKE ta có thể bật autoscaling như sau:
$ gcloud container clusters update kubia --enable-autoscaling \
--min-nodes=3 --max-nodes=5
Đối với các platforms khác, các bạn xem ở đây https://github.com/kubernetes/autoscaler/tree/master/cluster-autoscaler.
Scaling Levels
Chúng ta đã nói qua về những cách scale một ứng dụng lên, đây là hình minh họa về các kỹ thuật có thể được dùng để scale ứng dụng theo từng level khác nhau.
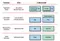
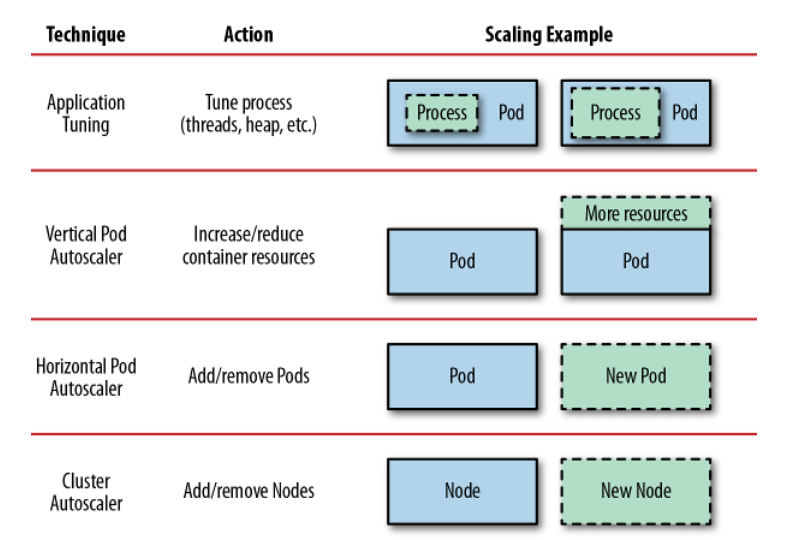
Application Tuning ta không có nói ở bài này, vì nó là các ta scale tùy thuộc vào cách viết ứng dụng, ở cách này ta sẽ scale process bên trong một container.
Horizontal Pod Autoscaling như ta đã nói, sẽ tăng số lượng Pod lên để thực hiện một tác vụ nào đó, sẽ giúp hiểu suất của ứng dụng của ta trở nên tốt hơn.
Vertical Pod Autoscaling thì sẽ tăng mức độ sử dụng tài nguyên của Pod lên, áp dụng cho những Pod nào không thể tách ra để chạy song song được, như AI model.
Cluster Autoscaling thì sẽ tăng số lượng worker node lên, khi ta không thể scale bằng cách Horizontal hoặc Vertical được nữa.
Kết luận
Vậy là ta đã tìm hiểu xong về các autoscaling bên trong kubernetes cluster, sử dụng Horizontal Pod Autoscaling, Vertical Pod Autoscaling một cách hợp lý sẽ giúp ứng dụng ta chạy cực kì tốt cho client. Nếu có thắc mắc hoặc cần giải thích rõ thêm chỗ nào thì các bạn có thể hỏi dưới phần comment. Ở bài tiếp theo, ta sẽ nói về cách làm sao để schedule một Pod tới những worker node ta muốn, có thể gọi là Advanced scheduling.