Tiếp nối bài viết trước với chủ đề Introduction to Recommender Systems ,mình sẽ tiếp tục cùng mọi người tìm hiều thêm về Matrix Factorization. Vì cũng phải dân chuyên trong lĩnh vực này nên mình sẽ dịch lại bài Recommendation Systems: Collaborative Filtering using Matrix Factorization — Simplified (để tiện theo dõi thì các bạn có thể đọc lại bài Giới thiệu về Hệ thống gợi ý của mình để hiểu nó là gì).
Nhiệm vụ của hệ thống
Chúng ta có một tập người dùng U và một tập sản phẩm I. Mục tiêu của hệ thống là giới thiệu một sản phẩm từ tập I cho người dùng dựa trên sở thích, dữ liệu trong quá khứ của họ. Để giải quyết vấn đề này, chúng ta phải tạo lập được một hàm cơ sở từ những dữ liệu trong quá khứ của người dùng để dự đoán mỗi sản phẩm i trong I có là một đề xuất phù hợp cho người dùng u trong U.
Lọc cộng tác
Phương pháp lọc cộng tác dựa trên việc thu thập và phân tích một lượng lớn thông tin về hành vi, sở thích, hoạt động người dùng và dự đoán những gì người dùng có thể thích dựa trên sự giống nhau của họ với người dùng khác. Giả định cơ bản của kỹ thuật lọc cộng tác là các sở thích tương tự của người dùng đối với các mục (sản phẩm) có thể được khai thác để giới thiệu các mục đó cho người dùng chưa từng xem hoặc sử dụng nó trước đây. Nói một cách đơn giản hơn, kỹ thuật giả định rằng những gì người dùng đã đồng ý trong quá khứ (mua cùng một sản phẩm hoặc xem cùng một bộ phim) sẽ vẫn đồng ý trong tương lai.

Matrix Factorization
Sau cuộc thi “Netflix Price Challenge”, Matrix Factorization là một trong những kỹ thuật lọc cộng tác được sử dụng phổ biến nhất. Để hiểu đơn về Matrix Factorization chúng ta sẽ sử dụng ví dụ về một hệ thống giới thiệu phim.Hãy giả sử các diễn viên sau đây là người dùng của hệ thống giới thiệu: Ben Affleck, Robert Downey Jr., Ryan Reynolds, Chris Evans, Henry Cavill. Danh sách những bộ phim được người dùng xem và đánh giá theo thang điểm 5 là: Avengers Infinity War, Batman vs Superman, Deadpool, Aquaman, Green Lantern. Để đơn giản hóa, chúng ta sẽ biểu thị chúng bằng cách sử dụng u1-u5 và i1-i5 tương ứng.

Từ ma trận đánh giá, có thể dễ dàng nhận thấy rằng u2 và u4 có sở thích phim tương tự nhau. Ngoài ra, u1 và u5 cũng có sở thích xem phim tương tự nhau. Và u3 là duy nhất, có sở thích/lịch sử xem phim không giống với những người dùng còn lại trong hệ thống. Matrix Factorization khai thác sự tương đồng giữa các người dùng trong các tùy chọn và tương tác của người dùng để cung cấp các đề xuất. Giả sử người dùng u4 không xem i5. Làm sao để biết người dùng u4 có thích i5 hay không?. Logic là tìm một người dùng có sở thích tương tự với người dùng đang hoạt động (user active) u4, lấy xếp hạng được đánh giá cho i5 bởi người dùng đó và giả sử đó là xếp hạng của u4 cho mục đó. Đánh giá này thu được từ sự tương tự của người dùng với những người dùng khác trong hệ thống, chúng tôi có thể biết liệu u4 có thích i5 hay không. Mục tiêu là tìm tất cả những người dùng phụ thuộc vào mục này trong Ma trận.
VD:
Giải pháp cho vấn đề này là Matrix Factorization. Vậy Factorization là gì? Hiểu một cách đơn giản Factorization là một phương pháp biểu diễn một cái gì lớn ví dụ như một sản phẩm thành những yếu tố nhỏ hơn.
Tương tự như vậy, Matrix Factorization tìm ra hai ma trận hình chữ nhật có kích thước nhỏ hơn để biểu thị một ma trận xếp hạng lớn (RM: Rating Matrix). Các ma trận nhỏ hơn này giữ lại các phụ thuộc và thuộc tính của ma trận đánh giá. Trong đó một ma trận có thể được xem là ma trận người dùng (UM: User Matix) vớicác hàng đại diện cho người dùng và các cột là k yếu tố tiềm ẩn (latent factors); ma trận còn lại là ma trận mục (IM: Item Matix) trong đó các hàng là k hệ số tiềm ẩn và các cột biểu thị các mục (item). Trong đó k < số lượng mục/sản phẩm và k < số lượng người dùng.
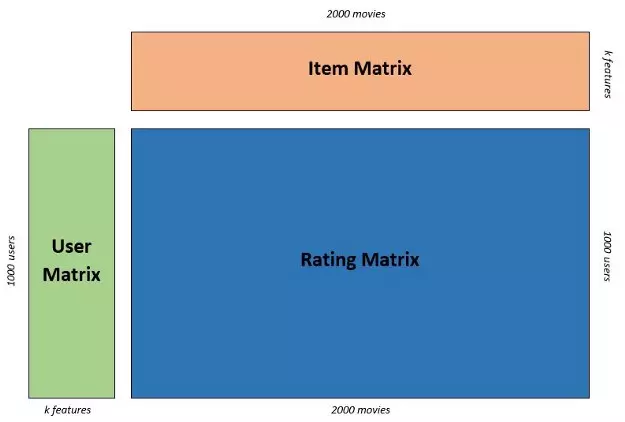
Các yếu tố tiềm ẩn (latent factors) hay được gọi theo cách khác là các đặc trưng (đặc điểm). Đặc trưng là đặc điểm nổi bật của một mục hay người dùng. Trong trường hợp của hệ thống giới thiệu phim, các đặc trưng của phim có thể là thể loại, diễn viên, cốt truyện, v.v. Các đặc điểm của Ma trận thừa số (matrix factorization) không liên quan đến giải pháp. Bây giờ ma trận xếp hạng được biểu diễn dưới dạng dot product của ma trận người dùng và sản phẩm.
Bây giờ chúng ta sẽ tìm hiểu về các đặc trưng và dot product của ma trận thừa số bằng cách sử dụng hình bên dưới. Chúng ta sẽ bỏ qua các xếp hạng khác trong hình ảnh ma trận đánh giá ban đầu để đơn giản hóa. Chúng ta sẽ giả định rằng ma trận thừa kế chỉ có hai đặc trưng F1 và F2. Giả sử chúng ta chọn F1 là "Nếu đó là một bộ phim với các nhân vật Marvel?" và F2 là “Nếu Ryan có trong phim?”.
Ma trận người dùng: Theo Ryan, nếu đó là một bộ phim Marvel, anh ấy sẽ cho nó 3 điểm và nếu anh ấy tham gia phim, anh ấy sẽ cho nó thêm 2 điểm.
Ma trận mục: Ma trận mục chứa các giá trị nhị phân trong đó giá trị là 1 nếu thỏa mãn các điều kiện của các đặc trưng nêu trên và ngược lại sẽ là 0. Bằng cách thực hiện dot product của ma trận người dùng và ma trận mục, Infinity War được 3 điểm và Deadpool nhận được 5 điểm.
Bây giờ câu hỏi quan trọng ở đây là:
"LÀM THẾ NÀO ĐỂ CHÚNG TA CÓ THỂ TÌM RA FACTORIZATION MATRIX PHÙ HỢP?"
Học máy là giải pháp giúp giải quyết vấn đề này. Mô hình học cách tìm các đặc trưng để phân tích ma trận đánh giá. Để đạt được giá trị gần đúng nhất của các yếu tố, RMSE (độ lệch chuẩn) là hàm mục tiêu cần được tối ưu hóa. Sau khi quá trình Matrix factorization được thực hiện xong, phương sai được tính cho mọi xếp hạng phim trong ma trận đánh giá và giá trị gốc của giá trị trung bình của các giá trị phương sai được giảm thiểu. Để tối ưu RMSE tìm hiểu các yếu tố thì Gradient Descent và Alternating Least Squares là hai kỹ thuật được sử dụng phổ biến nhất.
Làm thế nào để sử dụng factorization matrix cho hệ thống khuyến nghị? Công dụng và điểm vượt trội của factorization matrix là gì?
Trong thực tế, mọi người dùng sẽ không thể xem tất cả các bộ phim có thể có. Vì vậy, ma trận đánh giá sẽ trông trống hơn - Ma trận thưa thớt (Sparse Matrix). Trong trường hợp này, mô hình vẫn có thể học cách phân tích ma trận thưa thớt thành các ma trận thành phần, nhưng RMSE sẽ chỉ được tính cho các xếp hạng thực sự có trong ma trận. Sau khi có được các đặc trưng tốt nhất để ước lượng xếp hạng dựa trên dữ liệu hiện có, chúng ta thực hiện tính dot product của ma trận yếu tố để điền vào các mục còn thiếu trong ma trận đánh giá. Sau đó, những đánh giá được điền đầy đủ thông tin này được sử dụng để cung cấp các đề xuất cho người dùng.
Chủ đề này còn nhiều điều cần nghiên cứu hơn nữa như sử dụng thuật toán nào để giảm thiểu hàm lỗi và các kỹ thuật đề xuất khác. Như đã đề cập ở phần trên, chúng ta có thể giảm thiểu hàm lỗi bằng phương pháp Alternative Least Squares song song hóa quá trình học hoặc thuật toán tối ưu Gradient Descent. Những kiến thức đó sẽ được trình bày ở bài viết khác. ^^