Cuộc sống thời đại phát triển kéo theo lượng thông tin mỗi ngày một lớn, con người luôn bận rộn với những mục tiêu bản thân đề ra vì thế mà vấn đề thời gian luôn là nan giải đối với mỗi cá nhân chúng ta. Một cuốn sách dày, một lượng dữ liệu lớn luôn cần một khoảng thời gian nhất định để tiêu thụ. Khi ta muốn tìm tài liệu để chạy "deadline" gấp, hay muốn tìm một vài ý chính trong một tài liệu, thật khó khăn khi phải đọc hết một cuốn sách hay hàng tá các trang tài liệu khác nhau phải không nào ?
Chính vì thấu hiểu những vấn đề nan giải đó, tự động tóm tắt được ra đời. Ứng dụng công nghệ mới này không chỉ giúp chúng ta rút ngắn được thời gian đọc để làm được nhiều việc khác quan trọng hơn mà còn giúp ta giảm các cảm giác "stress" khi đọc quá nhiều tài liệu.
Ở series này, mình muốn giới thiệu cho các bạn về bài toán tóm tắt văn bản tự động và quy trình từng bước để xây dựng một mô hình tóm tắt văn bản.
Đầu tiên, chúng ta cùng tìm hiểu các khái niệm cơ bản về bài toán này nhé.
Lưu ý: Những nội dung dưới đây chỉ là cơ bản về các khái niệm học sâu được áp dụng cho mô hình bài toán này.
1. Giới thiệu bài toán:
Đầu tiên, chúng ta phải tìm hiểu khái niệm trước khi đi vào bài toán:
Tóm tắt là nhiệm vụ tạo ra một phiên bản ngắn hơn của một hoặc một số tài liệu mà vẫn giữ được hầu hết ý nghĩa của đầu vào.
Mục tiêu của tóm tắt văn bản tự động là tạo ra bản tóm tắt giống như cách con người tóm tắt. Đây là một bài toán đầy thách thức, vì thông thường con người sẽ đọc toàn bộ nội dung dựa trên sự hiểu biết của mình để viết lại một đoạn tóm tắt nhằm làm nổi bật ý chính của văn bản gốc. Nhưng vì máy tính khó có thể có được tri thức và khả năng như con người nên việc thực hiện tóm tắt văn bản tự động là một việc khá phức tạp.
Nhìn chung, có hai hướng tiếp cận khác cho trong bài toán Tóm tắt văn bản:
-
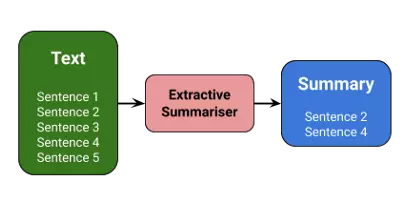
Tóm tắt trích xuất:
Phương pháp này tóm tắt các bài viết bằng cách chọn một tập hợp con các từ quan trọng trong bài viết. Cách tiếp cận này tập trung vào những phần quan trọng của các câu và sử dụng chúng để tạo ra phần tóm tắt. Sử dụng các thuật toán và kỹ thuật khác nhau để xác định trọng số cho các câu và xếp hạng chúng dựa trên mức độ quan trọng và độ giống nhau giữa các câu.
-
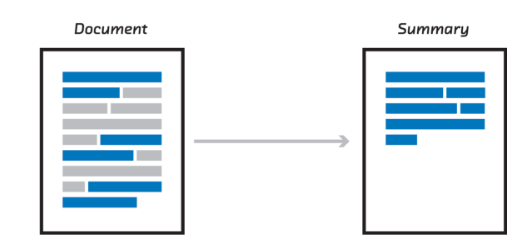
Tóm tắt trừu tượng:
Phương pháp trừu tượng này được tóm tắt dựa trên sự hiểu biết ngữ nghĩa nhằm mục đích tạo ra những đoạn tóm tắt theo một cách mới. Đây là một hướng tiếp cận mới mẻ và khá thú vị, thường được sử dụng các kỹ thuật xử lý ngôn ngữ tự nhiên tiên tiến tạo ra một đoạn văn bản mới chuyển tải được các thông tin quan trọng nhất từ vài viết gốc
Nhưng trước tiên, hãy cùng tìm hiểu về các khái niệm cần thiết trước khi đi sâu vào triển khai nó nhé!
2. Giới thiệu LSTM
Đầu tiên, bạn phải cần biết RNN là gì? RNN là một mạng nơ-ron hồi quy, đây là một mạng được thiết kế cho việc xử lý các loại dữ liệu có dạng chuỗi tuần tự. Bạn có thể tham khảo về RNN ở đây: https://dominhhai.github.io/vi/2017/10/what-is-lstm/
LSTM là một dạng đặc biệt của RNN, nó được thiết kế để giải quyết các bài toán về phụ thuộc xa trong mạng RNN (các mạng RNN cơ bản không thể thực hiện các khả năng ghi nhớ ở khoảng cách xa, do đó những phần tử đầu tiên của chuỗi không ảnh hưởng nhiều đến kết quả tính toán). Cấu trúc bên trong của LSTM:

3. Giới thiệu mô hình Sequence-to-Sequence (Seq2seq)
Chúng ta có thể sử dụng mô hình Seq2Seq cho nhiều bài toán như Machine Translation (dịch máy), Named Enity Recognition (Nhận diện thực thể có tên) hay Sentiment Classification (Phân loại cảm xúc).
Mục tiêu của chúng ta trong bài toán này là xây dựng một trình tóm tắt văn bản, với đầu vào là một chuỗi dài các từ (trong nội dung văn bản) và đầu ra là một bản tóm tắt ngắn (cũng là một chuỗi). Vì vậy chúng ta có thể thực hiện bài toán này bằng mô hình Many-to-many Seq2seq. Dưới đây là một số mô hình Seq2seq:

Mô hình Seq2seq sử dụng kiến trúc Encoder-Decoder có độ dài đầu vào và đầu ra khác nhau. Kiến trúc Encoder-Decoder được coi là hai khối - Mã hóa (Encoder) và Giải mã (Decoder), hai khối này được kết nối với nhau thông qua Vector trung gian (Context Vector):
-
Bộ mã hóa - Encoder: Bộ mã hóa xử lý từng token trong chuỗi đầu vào, và nó cố gắng nhồi nhét toàn bộ thông tin đầu vào vào một vector có độ dài cố định, tức là "vector trung gian". Sau đó bộ mã hóa sẽ chuển vector này sang bộ giải mã.
-
Vector trung gian - Context Vector: Vector này có chức năng gói gọn toàn bộ ý nghĩa của chuỗi đầu vào và giúp bộ giải mã đưa ra được quyết định chính xác. Đây là trạng thái ẩn nằm cuối chuỗi và được tính bởi bộ mã hóa, vector này sau đó cũng hoạt động như trạng thái ẩn đầu tiên của bộ giải mã.
-
Bộ giải mã - Decoder: Bộ giả mã sử dụng Vector trung gian và cố gắng dự đoán chuỗi đích.
Ở bài toán này, chúng ta sử dụng LSTM là một RNN cho mô hình Seq2Seq:

Hạn chế của mô hình Encoder
Vì bộ mã hóa chuyển đổi toàn bộ chuỗi đầu vào thành một vector có độ dài cố định và sau đó bộ giải mã dự đoán chuỗi đầu ra nên:
- Kiến trúc này chỉ hoạt động tốt với các chuỗi ngắn.
- Khó để bộ mã hóa ghi nhớ các chuỗi dài thành một vector có độ dài cố định.
Cơ chế Attention sinh ra để khắc phục vấn đề này. Nó nhằm mục đích dự đoán một từ bằng cách chỉ xem xét một vài phần cụ thể của chuỗi, thay vì toàn bộ chuỗi. Hãy cùng tìm hiểu nó ở phần sau nhé.
4. Giới thiệu cơ chế Attention (Cơ chế Chú ý)
Bây giờ hãy xét một ví dụ:
Input: "Which sport do you like most?"
Output: "I love cricket"
Từ "I" trong câu output có mối liên hệ với từ "you" trong input, tương tự từ "love" trong câu output lại có liên kết với từ "like" trong câu input. Vậy, thay vì nhìn vào tất cả những từ trong đầu vào thì chúng ta có thể tăng tầm quan trọng của một vài từ cụ thể của đầu vào có ý nghĩa đối với đầu ra. Đó là ý tưởng cơ bản của cơ chế Attention
Có hai cơ chế Attention khác nhau phụ thuộc vào vector trung gian:

-
Global Attention: Tất cả các trạng thái ẩn của bộ mã hóa được xem xét để tạo ra vector trung gian.
-
Local Attention: Chỉ một vài trạng thái ẩn của bộ mã hóa đựo xem xét và lấy ra để tạo vector trung gian.
5. Phương pháp đánh giá ROUGE
Rouge (viết tắt của Recall-Oriented Understudy for Gisting Evaluation) là một tập hợp các chỉ số để đánh giá việc Tóm tắt tự động các văn bản hay Dịch máy. Nó hoạt động bằng cách so sánh một bản tóm tắt hoặc bản dịch được tạo tự động với một tập hợp các bản tóm tắt tham chiếu (thường là do con người tạo ra).
Hai loại đánh giá được sử dụng trong bài này: ROUGE-N, ROUGE-L
ROUGE-N
Nó đo lường sự trùng lặp của n-gram giữa bản tóm tắt được tạo tự động và bản tóm tắt tham chiếu. Trong n-gam giá trị của N có thể thay đổi từ 1 đến n nhưng khi giá trị của n tăng thì chi phí tính toán cũng tăng nhanh. Các số liệu n-gram được sử dụng chủ yếu là uni và bi-gram.
Ví dụ về Rouge-2 (bi-gram) (Áp dụng tương tự uni-gram hay tri-gram)
Câu tóm tắt tham khảo: the cat was under the bed
Bigram: the cat, cat was, was under, under the, the bed
Câu tóm tắt dự đoán: the cat was found under the bed
Bi-gram: the cat, cat was, was found, found under, under the, the bed
Dựa vào bi-gram của 2 câu trên, ta có:
= = =
= = =
Kết quả ROUGE2-Precison cho thấy rằng, chỉ có 67% bi-gram dự đoán trùng lặp so với bi-gram của tóm tắt tham khảo. Và độ đo có thể giảm nếu phần tóm tắt dài hơn, và sẽ đặc biệt giảm nếu áp dụng phương pháp trừu tượng.
ROUGE-L
Tính toán chuỗi dài nhất khớp nhau giữa tóm tắt tham khảo và tóm tắt dự đoán. Mỗi câu trong văn bản được coi là một chuỗi các từ. Hai văn bản tóm tắt có chuỗi các từ phổ biến dài hơn thì giống nhau hơn.
6. Kết luận
Như vậy chúng ta đã tìm hiểu được mô hình Seq2seq,
Tài liệu tham khảo:
Mô hình Encoder-Decoder Seq2Seq: https://medium.com/analytics-vidhya/encoder-decoder-seq2seq-models-clearly-explained-c34186fbf49b