Nếu như Spectral (spectrum, phổ tín hiệu) có được bằng cách thực hiện biến đổi Fourier rời rạc (DFT) thì đặc trưng Cepstral có được bằng cách biến đổi DFT (hoặc DCT) spectrum của tín hiệu đó. Các đặc trưng cepstral như Mel-frequency cepstral coefficients (MFCC) được sử dụng rộng rãi trong các bài toán xử lý tiếng nói vì tính trực quan của nó. Trong bài này mình sẽ giới thiệu hai đặc trưng cepstral phổ biến là MFCC và Gammatone frequency cepstral coefficients (GFCC).
Mel-frequency cepstral coeficients
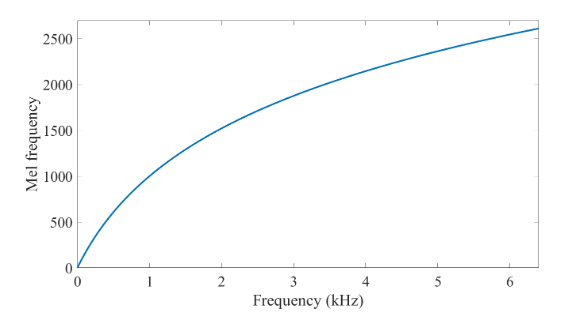
Trong xử lý âm thanh, mel-frequency cepstrum (MFC) là một biểu diễn của phổ năng lượng ngắn hạn của âm thanh, dựa trên biến đổi cosine tuyến tính của logarit phổ năng lượng trên thang tần số mel phi tuyến. Mel-frequency cepstral coefficients (MFCC) là các hệ số tạo thành một MFC. Thang tần số Mel được định nghĩa như sau:
Để trích xuất MFCC, sau khi chia âm thanh dạng waveform thành các frame, ta biến đổi Fourier rời rạc trên frame đó:
Trong đó là cửa sổ phân tích (Hamming, Hanning,...) độ dài và là độ dài của DFT. Sau đó, power spectrum của được tính bằng công thức:
Bằng cách lấy một tần số , ta sẽ ánh xạ được sang tần số trên thang Mel. Tuy nhiên, nếu chỉ chọn mẫu ở tần số , chúng ta sẽ mất tất cả các thông tin khác. Do đó, ta lấy tổng năng lượng có trọng số gần tần số mục tiêu trên power spectrum bằng công thức:
Trong đó là trọng số ứng với mẫu và thường là các bộ lọc tam giác:
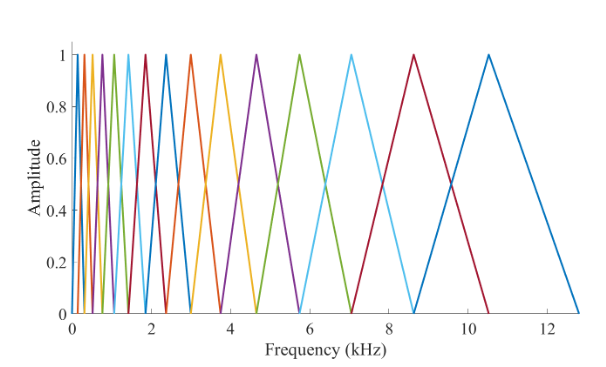
Cuối cùng, bằng cách biến đổi cosine rời rạc (DCT) của các tham số , chúng ta có được biểu diễn được gọi là Mel-frequency cepstral coefficients (MFCC). Tác dụng của DCT là làm giảm sự tuyến tính, sao cho các hệ số MFC không tương quan với nhau. (Ảnh: Từ trái qua phải: spectrogram, mel-spectrogram, MFCC)

Một số ưu điểm của MFCC:
- Loại bỏ những thông tin quá chi tiết (thường là dư thừa) và tập trung vào những thông tin về cấu trúc âm thanh (thường quan trọng hơn)
- Dễ hiểu và tính toán dễ dàng
- Hiệu quả đã được kiểm chứng
Những vấn đề của MFCC:
- Việc lựa chọn thang Mel chưa được kiểm chứng chặt chẽ bằng toán học. Các thang đo như ERB hoặc gammatone filterbank có thể phù hợp hơn. Tuy nhiên, các bộ lọc thay thế này không cho thấy lợi ích nhất quán trong các bài toán khác nhau, do đó thang đo mel vẫn được sử dụng.
- Nhạy cảm với nhiễu. Hiệu suất của các MFCC khi tín hiệu xuất hiện nhiễu, so với các đặc trưng khác không phải lúc nào cũng tốt hơn.
- Sự lựa chọn các bộ lọc tam giác thường là tự ý và không dựa trên một lập luận vững chắc nào
- Hoạt động tốt trong bài toán phân tích (analysis) nhưng không tốt trong bài toán tổng hợp (synthesis). Việc biến đổi ngược từ MFCC sang spectrogram rất khó khăn.
Gammatone frequency cepstral coefficients
Một trong những vấn đề lớn nhất trong nhận diện âm thanh là tiếng ồn/nhiễu. Độ nhạy đối với nhiễu, như đã đề cập ở trên, là một trong những nhược điểm chính của MFCC. GFCC là đặc trưng dựa trên một tập hợp các bộ lọc Gammatone. Đầu ra của bộ lọc gammatone là một biểu diễn trên miền thời gian-tần số, được gọi là cochleagram. Để tính toán GFCC, ta cần phải trích xuất cochleagram; các bước tính toán khác có nhiều điểm tương đồng với MFCC.
Đầu tiên, ta cũng thực hiện biến đổi STFT trên tín hiệu đầu vào:
Sau đó trích xuất power cepstrum trước khi nhân chập với các bộ lọc Gammatone:
Các bộ lọc Gammatone được thiết kế để mô phỏng quá trình xử lý tín hiệu của hệ thống thính giác của con người. Bộ lọc Gammatone có tần số trung tâm được định nghĩa là:
Trong đó là pha nhưng thường được đặt thành 0, hằng số điều khiển độ tăng (gain) và bậc của bộ lọc được xác định bởi giá trị (thường được đặt thành giá trị nhỏ hơn 4). Tham số b được định nghĩa là:
Hình dưới đây mô tả đáp ứng tần số của các bộ lọc gammatone.
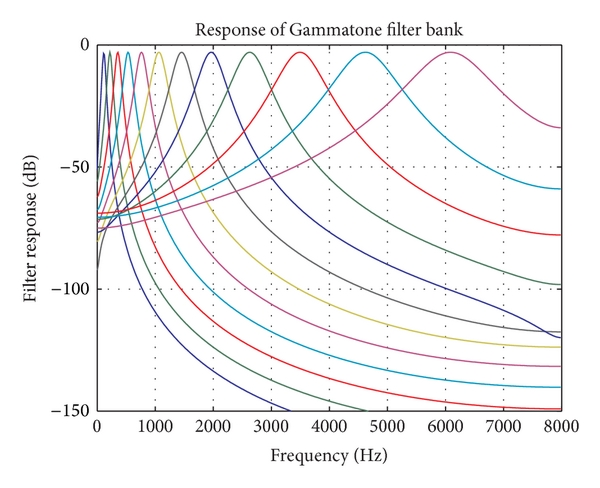
Ta thực hiện nhân chập với bộ lọc Gammatone để tạo ra Cochleagram:
Cochleagram được trích xuất tương tự như Mel-spectrogram trong MFCC, chỉ khác một điều rằng thay vì sử dụng bộ lọc tam giác như MFCC, ta sử dụng bộ lọc Gammatone như trên.
Biến đổi cosine rời rạc được áp dụng để thu được các hệ số cepstral phi tuyến. Tương tự như thao tác trên MFCC, hàm log được sử dụng trên spectrum :
trong đó khoảng giá trị của thường là từ 0 đến 31. 12 hệ số đầu tiên sau đó được chọn ra để tạo thành GFCC 12 chiều:
Ưu điểm của GFCC là ít nhạy cảm với nhiễu (so với MFCC) và mang nhiều thông tin ở vùng tần số thấp, dẫn đến phù hợp với các bàn toán xử lý tiếng nói. Tuy nhiên hiệu suất của GFCC cũng không nhất quán giữa các bài toán khác nhau và nó cũng ít được sử dụng hơn MFCC.
Kết luận
Hai đặc trưng MFCC và GFCC rất hiệu quả trong các bài toán tiếng nói. Chúng là những biểu diễn đủ tốt và đủ nhỏ nên hay được sử dụng cho các thuật toán Machine Learning. Đối với Deep Learning, các phiên bản spectrogram của hai đặc trưng này, là mel-spectrogram và cochleagram, được ưu ái hơn do chúng giữ lại nhiều thông tin, giúp các mô hình học sâu tự trích xuất được các đặc trưng hữu ích.
Tham khảo
https://wiki.aalto.fi/display/ITSP/Introduction+to+Speech+Processing
Gammatone and MFCC Features in Spreaker Recognition